When extracting fields from events in Splunk, typically each field has a single value. For instance, in a firewall packet event there is a src_ip, src_port, dest_ip, dest_port, action, etc., each with a single value. But there are occasionally fields which have more than one value. One common field type that often has multiple values is an e-mail address field, such as from or to. Splunk deals with these values by allowing fields to hold multiple values, which it refers to as simply a “multivalue field.” One place you see this in Check Point logs is in malware events, which sometimes report e-mail anomalies and include a to field. The Splunk Add-on for Check Point OPSEC LEA (the “LEA add-on”) parses the to field as a single value encompassing all of the addresses, making it hard to report on a specific address. We can fix this, at search time, using the TOKENIZER.
A typical malware event from Check Point looks like this:
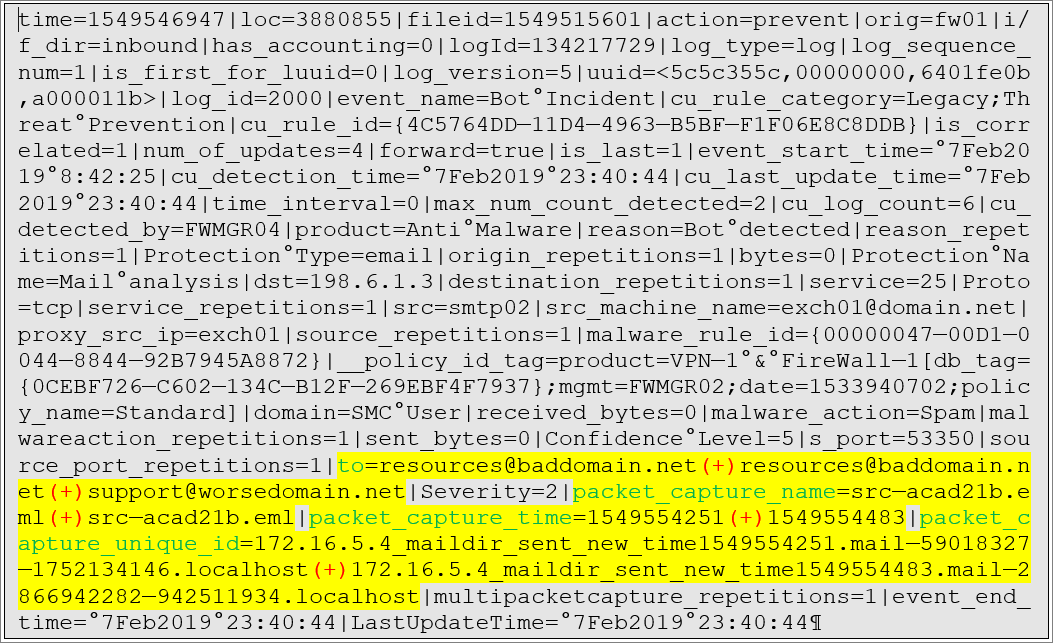
The fields are delimited by pipe characters with a key=value structure within the delimiters and the LEA add-on extracts these fields using a simple regex in default/transforms.conf:

In the case of the to field, an example of a resulting extracted value is:
resources@baddomain.net (+) resources@baddomain.net (+) support@worsedomain.net
which is valid but not as helpful as it could be. Those (+) characters are actually delimiters between multiple e-mail addresses. We would prefer that each of the addresses was broken out as a separate value in a multi-value to field.
We can, of course, do this at search time in SPL, using either makemv,

or using rex to extract the values back into the field,

But it would be preferable if this was done automatically by Splunk so we don’t have to include one of these functions in every search involving to. It’s probably best not to change the core extraction of the LEA add-on (though we could), but we can use another technique to parse the individual values of the to field after the full field has been extracted by the add-on. This is done with the TOKENIZER parameter in fields.conf.
According to the documentation for the fields.conf configuration file:

The regular expression to use in the file will be the same one we presented in the makemv example above, so you can test it out with makemv before putting it in fields.conf. Here’s what you need to do:
- Create a conf in Splunk_TA_checkpoint-opseclea\local (or you can put it in your own app that depends on the LEA add-on)
- Place the following stanza in conf:
[to]
TOKENIZER = ([^\(\+\)]+)
- the stanza name in square brackets is the name of the field to affect, here the “to” field,
- the value assigned to TOKENIZER is the regular expression to select a single instance of the field, here including characters up to an open parenthesis, a plus sign, or a close parenthesis
- Once you have saved the file, you can restart Splunk to be sure the change is adopted immediately, or you can just wait a bit until the knowledge bundle is downloaded to your search peers and try the search again. It should start working within 3 or 4 minutes.
Now, when you access the to field with the table or top or stats or timechart or similar commands, you should see a multivalue field with individual e-mail addresses for each value.
Before applying the TOKENIZER statement, a table showing “| stats count by to” would look like this:
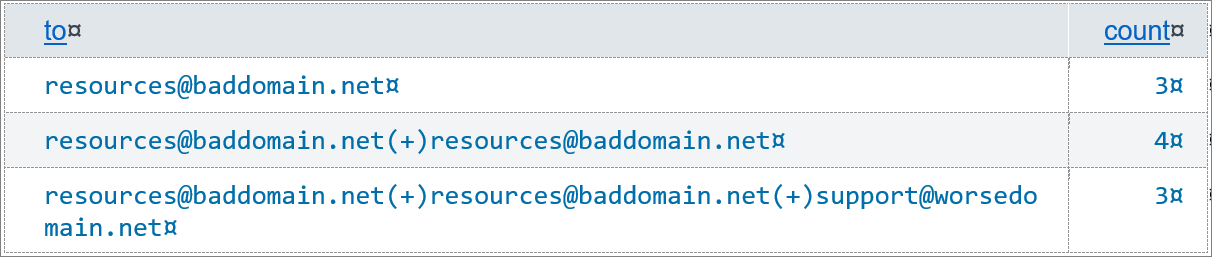
where the full value of to is considered as a single field. After making to a multivalue field, the same search results in this table:

This is a much more accurate report of the e-mail addresses found.
The same exercise can be followed for the packet_capture_name field, which might look like this:

the packet_capture_time field:

and the packet_capture_unique_id field:

all of which have the same (+) delimeters. Just add stanzas to fields.conf for each of those fields and use the same TOKENIZER regular expression for both.
Now when you report on any of these fields, you can be confident that you are showing an accurate representation of the information contained in your events. And you did it without overriding any of the LEA add-on’s extractions or requiring any additional SPL code in your searches.